Split arrays or matrices into random train and test subsets
Quick utility that wraps input val > next(ShuffleSplit().split(X, y)) and application to input data into a single call for splitting (and optionally subsampling) data in a oneliner.
Read more in the User Guide .
Parameters *arrays sequence of indexables with same length / shape[0]
Allowed inputs are lists, numpy arrays, scipy-sparse matrices or pandas dataframes.
test_size float, int or None, optional (default=None)
If float, should be between 0.0 and 1.0 and represent the proportion of the dataset to include in the test split. If int, represents the absolute number of test samples. If None, the value is set to the complement of the train size. If train_size is also None, it will be set to 0.25.
train_size float, int, or None, (default=None)
If float, should be between 0.0 and 1.0 and represent the proportion of the dataset to include in the train split. If int, represents the absolute number of train samples. If None, the value is automatically set to the complement of the test size.
random_state int, RandomState instance or None, optional (default=None)
If int, random_state is the seed used by the random number generator; If RandomState instance, random_state is the random number generator; If None, the random number generator is the RandomState instance used by np.random .
shuffle boolean, optional (default=True)
Whether or not to shuffle the data before splitting. If shuffle=False then stratify must be None.
stratify array-like or None (default=None)
If not None, data is split in a stratified fashion, using this as the class labels.
Returns splitting list, length=2 * len(arrays)
List containing train-test split of inputs.
Data is infinite. Data scientists have to deal with that every day!
Sometimes we have data, we have features and we want to try to predict what can happen.
To do that, data scientists put that data in a Machine Learning to create a Model.
Let’s set an example:
- A computer must decide if a photo contains a cat or dog.
- The computer has a training phase and testing phase to learn how to do it.
- Data scientists collect thousands of photos of cats and dogs.
- That data must be split into training set and testing test.
Then is when split comes in.
Train test split
Split
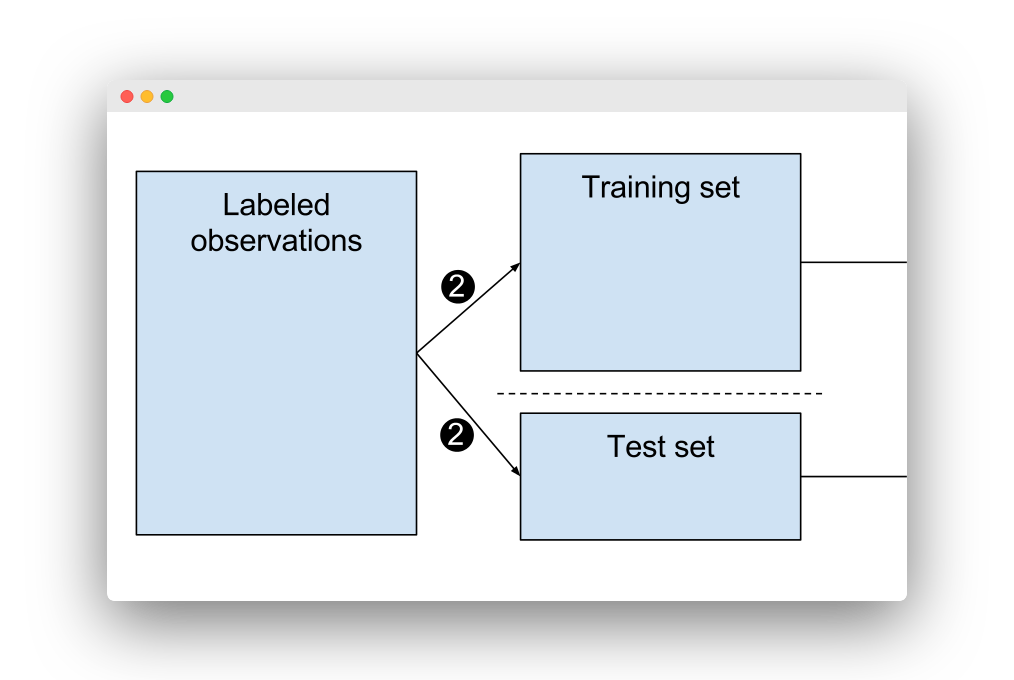
Knowing that we can’t test over the same data we train, because the result will be suspicious… How we can know what percentage of data use to training and to test?
Easy, we have two datasets.
- One has independent features, called (x).
- One has dependent variables, called (y).
To split it, we do:
x Train – x Test / y Train – y Test
That’s a simple formula, right?
x Train and y Train become data for the machine learning, capable to create a model.
Once the model is created, input x Test and the output should be equal to y Test.
The more closely the model output is to y Test: the more accurate the model is.
Then split, lets take 33% for testing set (whats left for training).
You can verify you have two sets:
Data scientists can split the data for statistics and machine learning into two or three subsets.
- Two subsets will be training and testing.
- Three subsets will be training, validation and testing.
Anyways, scientists want to do predictions creating a model and testing the data.
When they do that, two things can happen: overfitting and underfitting.
Overfitting
Overfitting is most common than Underfitting, but none should happen in order to avoid affect the predictability of the model.
So, what that means?
Overfitting can happen when the model is too complex.
Overfitting means that the model we trained has trained “too well” and fit too closely to the training dataset.
But if it’s too well, why there’s a problem? The problem is that the accuracy on the training data will unable accurate on untrained or new data.
To avoid it, the data can’t have many features/variables compared to the number of observations.
Underfitting
What about Underfitting?
Underfitting can happen when the model is too simple and means that the model does not fit the training data.
To avoid it, the data need enough predictors/independent variables.
Before, we’ve mentioned Validation.
Validation
Cross Validation is when scientists split the data into (k) subsets, and train on k-1 one of those subset.
The last subset is the one used for the test.
Some libraries are most common used to do training and testing.
- Pandas: used to load the data file as a Pandas data frame and analyze it.
- Sklearn: used to import the datasets module, load a sample dataset and run a linear regression.
- Matplotlib: using pyplot to plot graphs of the data.
Finally, if you need to split database, first avoid the Overfitting or Underfitting.
Do the training and testing phase (and cross validation if you want).
Use the libraries that suits better to the job needed.
Machine learning is here to help, but you have to how to use it well.
I need to split my data into a training set (75%) and test set (25%). I currently do that with the code below:
However, I’d like to stratify my training dataset. How do I do that? I’ve been looking into the StratifiedKFold method, but doesn’t let me specifiy the 75%/25% split and only stratify the training dataset.
6 Answers 6
There is a pull request here. But you can simply do train, test = next(iter(StratifiedKFold(. ))) and use the train and test indices if you want.
TL;DR : Use StratifiedShuffleSplit with test_size=0.25
Scikit-learn provides two modules for Stratified Splitting:
- StratifiedKFold : This module is useful as a direct k-fold cross-validation operator: as in it will set up n_folds training/testing sets such that classes are equally balanced in both.
Heres some code(directly from above documentation)
- StratifiedShuffleSplit : This module creates a single training/testing set having equally balanced(stratified) classes. Essentially this is what you want with the n_iter=1 . You can mention the test-size here same as in train_test_split