Выборка уникальных значений. Оператор DISTINCT
С помощью оператора DISTINCT можно выбрать уникальные данные по определенным столбцам.
К примеру, разные товары могут иметь одних и тех же производителей, и, допустим, у нас следующая таблица товаров:
Выберем всех производителей:
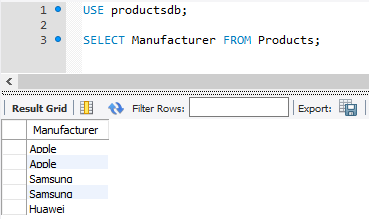
Однако при таком запросе производители повторяются. Теперь применим оператор DISTINCT для выборки уникальных значений:
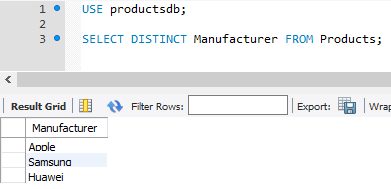
Также мы можем задавать выборку уникальных значений по нескольким столбцам:
В данном случае для выборки используются столбцы Manufacturer и ProductCount. Из пяти строк только для двух строк эти столбцы имеют повторяющиеся значения. Поэтому в выборке будет 4 строки:
Встречаются ситуации когда необходимо сделать выборку не повторяющихся (уникальных) значений из како-нибудь таблицы. Например из таблицы посещений пользователей выбрать только уникальные id или из истории заказов интернет-магазина.
Есть, к-примеру, такая таблица.
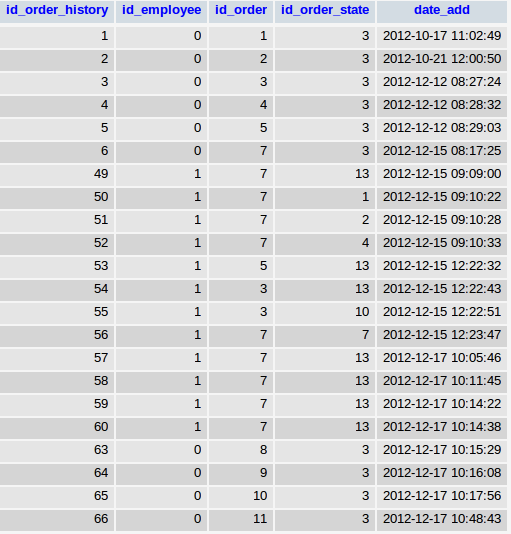
Нужно получить все уникальные id_order.
Рассмотрим теперь, как выбрать и вывести записи таблиц MySQL с помощью ключевого слова DISTINCT (РАЗЛИЧНЫЙ), использование которого исключает появление повторяющихся данных.
Запрос выглядит так:
В результате будут такие данные:
И самая сложная выборка — выборка последних значений (с максимальным id) среди различных групп записей.
Допустим, есть таблица, в которой хранятся записи с такими полями: id, note_id, date.
id — уникальные. note_id — не уникальные, номер соответствует номеру страницы с записями, имеющими разные даты (поле date).
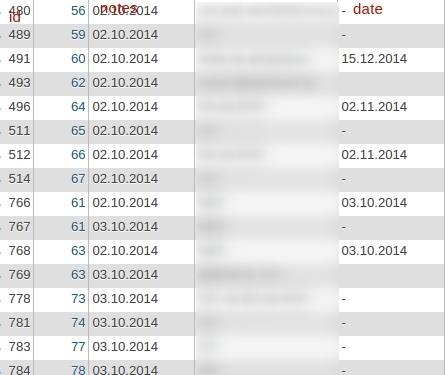
Задача — выбрать записи note с максимальным id и датой как условием.
Таким образом можно получить записи, содержащие только указанную дату в качестве условия.
Если убрать условие WHERE ‘date’ LIKE ‘%03.11.2014%’, то можно получить просто самые последние записи.
Есть таблица org (name, emp_id). Для каждого возможного значения name , необходимо вывести количество уникальных emp_id . Можно ли это сделать с помощью count() или как ещё?
UPD: Немного расшифрую. Допустим
В результате необходимо получить что-то вроде
т.е. если emp_id повторяется в разных name , то их необходимо подсчитывать
4 ответа 4
Первая интерпретация вашего вопроса Для каждого name подсчитать уникальное количество emp_id
Вторая интерпретация, подсчитать так, что бы исключить emp_id встречающиеся у разных name Для этого пойдем от обратного подсчитаем количество name у emp_id , то есть нам необходимо исключить из выборки emp_id встречающиеся у нескольких name
Унифицировать или нет дело ваше, смотря что там лежит и как