Выборка уникальных значений. Оператор DISTINCT
С помощью оператора DISTINCT можно выбрать уникальные данные по определенным столбцам.
К примеру, разные товары могут иметь одних и тех же производителей, и, допустим, у нас следующая таблица товаров:
Выберем всех производителей:
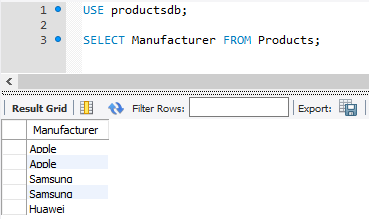
Однако при таком запросе производители повторяются. Теперь применим оператор DISTINCT для выборки уникальных значений:
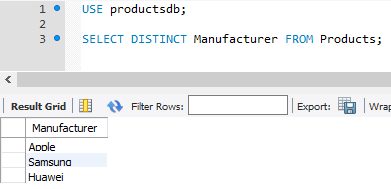
Также мы можем задавать выборку уникальных значений по нескольким столбцам:
В данном случае для выборки используются столбцы Manufacturer и ProductCount. Из пяти строк только для двух строк эти столбцы имеют повторяющиеся значения. Поэтому в выборке будет 4 строки:
Встречаются ситуации когда необходимо сделать выборку не повторяющихся (уникальных) значений из како-нибудь таблицы. Например из таблицы посещений пользователей выбрать только уникальные id или из истории заказов интернет-магазина.
Есть, к-примеру, такая таблица.
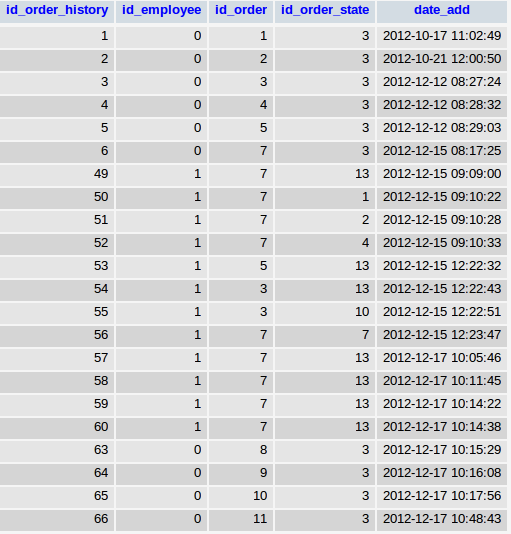
Нужно получить все уникальные id_order.
Рассмотрим теперь, как выбрать и вывести записи таблиц MySQL с помощью ключевого слова DISTINCT (РАЗЛИЧНЫЙ), использование которого исключает появление повторяющихся данных.
Запрос выглядит так:
В результате будут такие данные:
И самая сложная выборка — выборка последних значений (с максимальным id) среди различных групп записей.
Допустим, есть таблица, в которой хранятся записи с такими полями: id, note_id, date.
id — уникальные. note_id — не уникальные, номер соответствует номеру страницы с записями, имеющими разные даты (поле date).
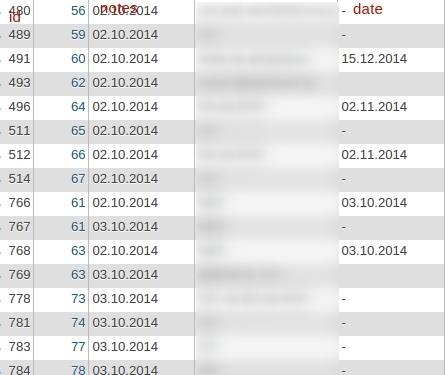
Задача — выбрать записи note с максимальным id и датой как условием.
Таким образом можно получить записи, содержащие только указанную дату в качестве условия.
Если убрать условие WHERE ‘date’ LIKE ‘%03.11.2014%’, то можно получить просто самые последние записи.
SQL: Как выбрать только уникальные (неповторяющиеся) записи
SELECT DISTINCT .
Отфильтровать все повторяющиеся записи с результата запроса можно с помощью DISTINCT.
Пример использования:
Допустим у нас есть таблица «winners» с данными:
| id | winner_name |
|---|---|
| 1 | Nick |
| 2 | Ann |
| 3 | Ann |
| 4 | David |
| 5 | Nick |
| 6 | Nick |
| 7 | Natali |
Допустим нам нужно получить список всех уникальный имён победителей.
Выполнив следующий запрос, мы получим все неповторяющиеся имена:
SELECT DISTINCT winner_name FROM winners;
Результат запроса:
| winner_name |
|---|
| Nick |
| Ann |
| David |
| Natali |
15 комментариев на «SQL: Как выбрать только уникальные (неповторяющиеся) записи»
Спасибо огромное, помогло!)
как в php сделать вывод данных?
Как я искал подобное решение. Огромное вам спасибо!
А как удалить неуникальные??
а еще можно использовать group by :
SELECT Filed FROM Table GROUP BY Field;
А если нужен и столбец id? подходит любое из значений… например
id winner_name
1 Nick
2 Ann
4 David
5 Nick
7 Natali
как такой запрос может выглядеть?
Так же есть задача, похожая на предыдущую. Есть таблица с вопросами из разных тем для экзамена. Нужно выбрать по одному случайному вопросу из 2-х любых тем (например так).
id theme question
1 1 question1
2 1 question2
3 1 question3
4 2 question4
5 2 question5
6 3 question6
7 3 question7
Тут решение из составного запроса в котором случайно сортируются все вопросы и берутся только 2 различные темы и потом как сделать, чтобы вопросов было по одному… Если кто знает — помогите, пожалуйста